Top Most Data Base Information

Oracle Database Architecture
{kind=link}
An Oracle database is a collection of data treated as a unit. The purpose of a database is to store and retrieve related information. A database server is the key to solving the problems of information management. In general, a server reliably manages a large amount of data in a multiuser environment so that many users can concurrently access the same data. All this is accomplished while delivering high performance. A database server also prevents unauthorized access and provides efficient solutions for failure recovery.Oracle Database is the first database designed for enterprise grid computing, the most flexible and cost effective way to manage information and applications. Enterprise grid computing creates large pools of industry-standard, modular storage and servers. With this architecture, each new system can be rapidly provisioned from the pool of components. There is no need for peak workloads, because capacity can be easily added or reallocated from the resource pools as needed.The database has logical structures and physical structures. Because the physical and logical structures are separate, the physical storage of data can be managed without affecting the access to logical storage structures.
If you need more information Please click on below link
Oracle Tutorials

General information about DB2(R) architecture and processes can help you understand detailed information provided for specific topics.
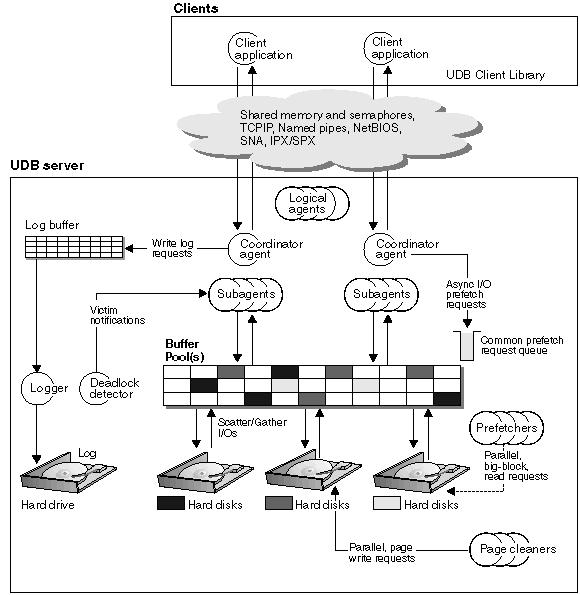 The following figure shows a general overview of the architecture and processes for DB2 UDB.
The following figure shows a general overview of the architecture and processes for DB2 UDB. On the client side, either local or remote applications, or both, are linked with the DB2 Universal Database(TM) client library. Local clients communicate using shared memory and semaphores; remote clients use a protocol such as Named Pipes (NPIPE), TCP/IP, NetBIOS, or SNA.
On the server side, activity is controlled by engine dispatchable units (EDUs). In all figures in this section, EDUs are shown as circles or groups of circles. EDUs are implemented as threads in a single process on Windows(R)-based platforms and as processes on UNIX(R). DB2 agents are the most common type of EDUs. These agents perform most of the SQL processing on behalf of applications. Prefetchers and page cleaners are other common EDUs.
A set of subagents might be assigned to process the client application requests. Multiple subagents can be assigned if the machine where the server resides has multiple processors or is part of a partitioned database. For example, in a symmetric multiprocessing (SMP) environment, multiple SMP subagents can exploit the many processors.
All agents and subagents are managed using a pooling algorithm that minimizes the creation and destruction of EDUs.
The configuration of the buffer pools, as well as prefetcher and page cleaner EDUs, controls how quickly data can be accessed and how readily available it is to applications.
•Prefetchers retrieve data from disk and move it into the buffer pool before applications need the data. For example, applications needing to scan through large volumes of data would have to wait for data to be moved from disk into the buffer pool if there were no data prefetchers. Agents of the application send asynchronous read-ahead requests to a common prefetch queue. As prefetchers become available, they implement those requests by using big-block or scatter-read input operations to bring the requested pages from disk to the buffer pool. If you have multiple disks for storage of the database data, the data can be striped across the disks. Striping data lets the prefetchers use multiple disks at the same time to retrieve data.
•Page cleaners move data from the buffer pool back out to disk. Page cleaners are background EDUs that are independent of the application agents. They look for pages from the buffer pool that are no longer needed and write the pages to disk. Page cleaners ensure that there is room in the buffer pool for the pages being retrieved by the prefetchers.
Without the independent prefetchers and the page cleaner EDUs, the application agents would have to do all of the reading and writing of data between the buffer pool and disk storage.
The DB2 process model
Knowledge of the DB2® process model helps you to understand how the database manager and its associated components interact. This knowledge can help you to troubleshoot problems that might arise.
The process model that is used by all DB2 database servers facilitates communication between database servers and clients. It also ensures that database applications are isolated from resources, such as database control blocks and critical database files.
The DB2 database server must perform many different tasks, such as processing database application requests or ensuring that log records are written out to disk. Each task is typically performed by a separate engine dispatchable unit (EDU).
There are many advantages to using a multithreaded architecture for the DB2 database server. A new thread requires less memory and fewer operating system resources than a process, because some operating system resources can be shared among all threads within the same process. Moreover, on some platforms, the context switch time for threads is less than that for processes, which can improve performance. Using a threaded model on all platforms makes the DB2 database server easier to configure, because it is simpler to allocate more EDUs when needed, and it is possible to dynamically allocate memory that must be shared by multiple EDUs.
For each database accessed, separate EDUs are started to deal with various database tasks such as prefetching, communication, and logging. Database agents are a special class of EDU that are created to handle application requests for a database.
In general, you can rely on the DB2 database server to manage the set of EDUs. However, there are DB2 tools that look at the EDUs. For example, you can use the db2pd command with the -edus option to list all EDU threads that are active.
Each client application connection has a single coordinator agent that operates on a database. A coordinator agent works on behalf of an application, and communicates to other agents by using private memory, interprocess communication (IPC), or remote communication protocols, as needed.
While in a DB2 pureScale® instance, these processes are used to monitor the health of DB2 members and/or cluster caching facilities (CFs) running on the host, as well as to distribute the cluster state to all DB2 members and CFs in the instance.
The DB2 architecture provides a firewall so that applications run in a different address space than the DB2 database server (Figure 1). The firewall protects the database and the database manager from applications, stored procedures, and user-defined functions (UDFs). The firewall maintains the integrity of the data in the databases, because it prevents application programming errors from overwriting internal buffers or database manager files. The firewall also improves reliability, because application errors cannot crash the database manager.
Figure 1. Process model for DB2 database systems

Client programs
Client programs can be remote or local,
running on the same machine as the database server. Client programs make first
contact with a database through a communication listener.
Listeners
Communication listeners start when the
DB2 database server starts. There is a listener for each configured
communications protocol, and an interprocess communications (IPC) listener
(db2ipccm)
for local client programs. Listeners include:
- db2ipccm, for local client connections
- db2tcpcm, for TCP/IP connections
- db2tcpdm, for TCP/IP discovery tool requests
Agents
All connection requests from local or
remote client programs (applications) are allocated a corresponding coordinator
agent (db2agent). When the coordinator agent is created, it performs
all database requests on behalf of the application.
In partitioned database environments, or
systems on which intraquery
parallelism is enabled, the coordinator agent distributes database requests
to subagents (db2agntp and db2agnts). Subagents that are associated with an application
but that are currently idle are named db2agnta.
A coordinator agent might be:
- Connected to the database with an alias; for example, db2agent (DATA1) is connected to the database alias DATA1.
- Attached to an instance; for example, db2agent (user1) is attached to the instance user1.
The DB2 database server instantiates other
types of agents, such as independent coordinator agents or subcoordinator
agents, to execute specific operations. For example, the independent coordinator
agent db2agnti is used to run event monitors, and the
subcoordinator agent db2agnsc is used to parallelize database restart operations
after an abnormal shutdown.
A gateway agent (db2agentg) is an agent associated to
a remote database. It provides indirect connectivity that allows clients to
access the host database.
Idle agents reside in an agent pool. These
agents are available for requests from coordinator agents that operate on behalf
of client programs, or from subagents that operate on behalf of existing
coordinator agents. Having an appropriately sized idle agent pool can improve
performance when there are significant application workloads. In this case, idle
agents can be used as soon as they are required, and there is no need to
allocate a new agent for each application connection, which involves creating a
thread and allocating and initializing memory and other resources. The DB2
database server automatically manages the size of the idle agent pool.
A pooled agent can be associated to a
remote database or a local database. An agent pooled on a remote database is
referred to as a pooled gateway agent (db2agntgp). An agent pooled on a
local database is referred to as a pooled database agent (db2agentdp).
db2fmp
The fenced mode process is responsible for
executing fenced stored procedures and user-defined functions outside of the
firewall. The db2fmp process is always a separate process, but might be
multithreaded, depending on the types of routines that it executes.
db2vend
The db2vend process is a process to
execute vendor code on behalf of an EDU; for example, to execute a user exit
program for log archiving (UNIX only).
Database EDUs
The following list includes some of
the important EDUs that are used by each database:
- db2pfchr, for buffer pool prefetchers
- db2pclnr, for buffer pool page cleaners
- db2dlock, for deadlock detection. In a partitioned database environment, an additional thread (db2glock) is used to coordinate the information that is collected by the db2dlock EDU on each partition; db2glock runs only on the catalog partition. In a DB2 pureScale environment, a db2glock EDU is used to coordinate the information that is collected by the db2dlock EDU on each member. A db2glock EDU is started on each member, but only one is active.
- db2fw, the event monitor fast writer;
which is used for high volume, parallel writing of event monitor data to tables,
files, or pipes
- db2fwx, an event monitor fast writer thread where "x" identifies the thread number. During database activation the DB2 engine sets the number of db2fwx threads to a value that is optimal for the performance of event monitors and avoids potential performance problems when different types of workloads are run. The number of db2fwx threads equals the number of logical CPUs on the system (for multi-core CPUs, each core counts as one logical CPU). For instances in a partitioned database environment, the number of db2fwx threads spawned equals to the number of logical CPUs per member, per database divided by the number of local partitions on the host.
- db2hadrp, the high availability disaster recovery (HADR) primary server thread
- db2hadrs, the HADR standby server thread
- db2lfr, for log file readers that process individual log files
- db2loggr, for manipulating log files to handle transaction processing and recovery
- db2loggw, for writing log records to the log files
- db2logmgr, for the log manager. Manages log files for a recoverable database.
- db2logts, for tracking which table spaces have log records in which log files. This information is recorded in the DB2TSCHG.HIS file in the database directory.
- db2lragen, for generating log sequence numbers with a new central server thread model if a valid XML resource policy is defined with a database scope. This might improve performance in very large NUMA systems, with very high update rates.
- db2lused, for updating object usage
- db2pcsd, for autonomic cleanup of the package cache
- db2redom, for the redo master. During recovery, it processes redo log records and assigns log records to redo workers for processing.
- db2redow, for the redo workers. During recovery, it processes redo log records at the request of the redo master.
- db2shred, for processing individual log records within log pages
- db2stmm, for the self-tuning memory management feature
- db2taskd, for the distribution of background database tasks. These tasks are executed by threads called db2taskp.
- db2wlmd, for automatic collection of workload management statistics
- Event monitor threads are identified
as follows:
- db2evm%1%2 (%3)
where %1 can be:
- g - global file event monitor
- gp - global piped event monitor
- l - local file event monitor
- lp - local piped event monitor
- t - table event monitor
- i - coordinator
- p - not coordinator
- db2evm%1%2 (%3)
- Backup and restore threads are
identified as follows:
- db2bm.%1.%2 (backup and restore buffer manipulator) and
db2med.%1.%2 (backup and restore media
controller), where:
- %1 is the EDU ID of the agent that controls the backup or restore session
- %2 is a sequential value that is used to distinguish among (possibly many) threads that belong to a particular backup or restore session
- db2bm.%1.%2 (backup and restore buffer manipulator) and
db2med.%1.%2 (backup and restore media
controller), where:
- The following database EDUs are used
for locking in a DB2
pureScale environment:
- db2LLMn1, to process information sent by the global lock manager; there are two of these EDUs on each member, one for the primary CF, and another for the secondary CF
- db2LLMn2, to process information sent by the global lock manager for a special type of lock that is used during database activation and deactivation processing; there are two of these EDUs on each member, one for the primary CF, and another for the secondary CF
- db2LLMng, to ensure that the locks held by this member are released in a timely manner when other members are waiting for these locks
- db2LLMrl, to process the release of locks to the global lock manager
- db2LLMrc, for processing that occurs during database recovery operations and during CF recovery
Database server threads and processes
The system controller (db2sysc on UNIX
and db2syscs.exe on Windows operating systems) must exist if the
database server is to function. The following threads and processes carry out
various tasks:
- db2acd, an autonomic computing daemon that hosts the health monitor, automatic maintenance utilities, and the administrative task scheduler. This process was formerly known as db2hmon.
- db2aiothr, manages asynchronous I/O requests for a database partition (UNIX only)
- db2alarm, notifies EDUs when their requested timer expires (UNIX only)
- db2disp, the client connection concentrator dispatcher
- db2fcms, the fast communications manager sender daemon
- db2fcmr, the fast communications manager receiver daemon
- db2fmd, the fault monitor daemon
- db2licc, manages installed DB2 licenses
- db2panic, the panic agent, which handles urgent requests after agent limits are reached
- db2pdbc, the parallel system controller, which handles parallel requests from remote database partitions (used only in a partitioned database environment)
- db2resync, the resync agent that scans the global resync list
- db2rocm and db2rocme, while in a DB2 pureScale instance, these processes monitor the operational state of DB2 members and cluster caching facilities (CFs) running on each host, as well as to distribute cluster state information to all DB2 members and CFs in the instance.
- db2sysc, the main system controller EDU; it handles critical DB2 server events
- db2sysc (idle), the DB2 idle processes, which enable the restart light of a guest member on a host quickly and without competing with the resident member for resources.
- db2thcln, recycles resources when an EDU terminates (UNIX only)
- db2wdog, the watchdog on UNIX and Linux operating systems that handles abnormal terminations
- db2wlmt, the WLM dispatcher scheduling thread
- db2wlmtm, the WLM dispatcher timer thread
DB2 Tutorials

TERADATA Introduction:
Teradata is an enterprise software company that develops and sells a relational database management system (RDBMS) with the same name. In February 2011, Gartner ranked Teradata as one of the leading companies in data warehousing and enterprise analytics.[4] Teradata was a division of the NCR Corporation, which acquired Teradata on February 28, 1991. Teradata's revenues in 2005 were almost $1.5 billion with an operating margin of 21%.[3] On January 8, 2007, NCR announced that it would spin-off Teradata as an independently traded company,[5] and this spin-off was completed October 1 of the same year, with Teradata trading under the NYSE stock symbol TDC.[6]
The Teradata product is referred to as a "data warehouse system" and stores and manages data. The data warehouses use a "shared nothing architecture,"[citation needed] which means that each server node has its own memory and processing power. Adding more servers and nodes increases the amount of data that can be stored. The database software sits on top of the servers and spreads the workload among them.[7] Teradata sells applications and software to process different types of data. In 2010, Teradata added text analytics to track unstructured data, such as word processor documents.
If you need more information Please click on below link
Teradata Basics:
SQL Server Architecture
Microsoft® SQL Server™ 2000 is a set of components that work together to meet the data storage and analysis needs of the largest Web sites and enterprise data processing systems. The topics in SQL Server Architecture describe how the various components work together to manage data effectively.
| Topic | Description |
|---|---|
| Features of SQL Server 2000 | Highlights the features of Microsoft SQL Server 2000. |
| Relational Database Components | Describes the main relational database components of SQL Server 2000, including the database engine itself and the components involved in communications between applications and the database engine. |
| Database Architecture | Describes the logical components defined in SQL Server databases and how they are physically implemented in database files. |
| Relational Database Engine Architecture | Describes the features of the server engine that make it efficient at processing large numbers of concurrent requests for data from many users. |
| Administration Architecture | Describes how the easy-to-use tools provided with SQL Server 2000 and the dynamic configuration capabilities of SQL Server minimize routine administrative tasks. |
| Replication Architecture | Describes the replication components of SQL Server 2000 and how they can be used to distribute data between databases. |
| Data Warehousing and Online Analytical Processing | Describes Data Transformation Services (DTS) and Microsoft SQL Server 2000 Analysis Services, and how they help in building and analyzing a data warehouse or data mart. |
| Application Development Architecture | Describes how SQL Server 2000 supports the various database programming APIs, which allow users to build robust database applications. |
| Implementation Details | Provides implementation details, such as the maximum capacities of Transact-SQL statements, the ranges of SQL Server configuration options, memory usage of SQL Server objects, and the differences among the editions of Microsoft SQL Server. |
If you need more information Please click on below link
SQL Tutorials
SQL Server Tutorials
SQL Server Basics
No comments:
Post a Comment